CNN implementation: initialisation, forward pass, backward pass, SGD-with-momentum update. More...
Functions | |
| static float | randn (void) |
| Box-Muller transform: sample one value from N(0, 1). | |
| static void | relu_inplace (float *x, size_t length) |
| Apply ReLU element-wise: f(x) = max(0, x). | |
| static void | softmax_inplace (float *x, size_t length) |
| Apply softmax in-place over an array of length n. | |
| CNN * | cnn_create (void) |
| Allocate and initialise a CNN with He-initialised weights. | |
| void | cnn_free (CNN *net) |
| Free all memory associated with a CNN. | |
| static void | forward_conv (CNN *net) |
| Convolution stage: compute net->act.conv_out. | |
| static void | forward_pool (CNN *net) |
| Max-pooling stage: compute net->act.pool_out. | |
| static void | forward_flatten (CNN *net) |
| Flatten stage: copy pool_out into act->flat, row-major. | |
| static void | forward_dense1 (CNN *net) |
| Dense layer 1 (2704 → 128) followed by ReLU. | |
| static void | forward_dense2 (CNN *net) |
| Dense layer 2 (128 → 26) followed by Softmax. | |
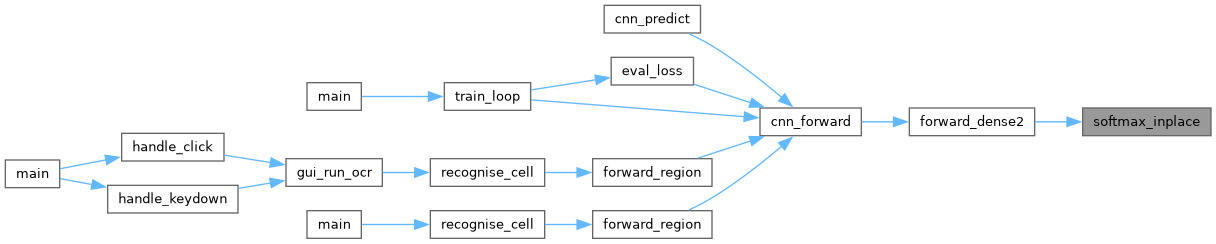
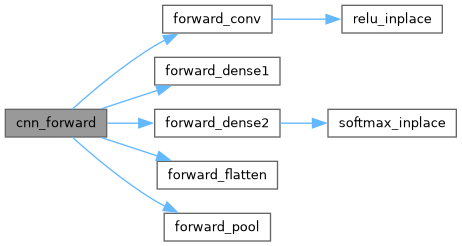
| void | cnn_forward (CNN *net, const float *image) |
| Run a full forward pass and populate net->act. | |
| float | cnn_loss (const CNN *net, int label) |
| Compute cross-entropy loss for the current forward-pass output. | |
| void | cnn_backward (CNN *net, int label) |
| Compute gradients via backpropagation. | |
| void | cnn_zero_grads (CNN *net) |
| Zero all gradient accumulators in net->grads. | |
| static void | sgd_update (float *w, float *v, const float *g, size_t n, float inv_batch) |
| Apply SGD+momentum to one weight array. | |
| void | cnn_update (CNN *net) |
| Apply one SGD-with-momentum update step to the weights. | |
| int | cnn_predict (CNN *net, const float *image) |
| Predict the most likely class for a single image. | |
Detailed Description
CNN implementation: initialisation, forward pass, backward pass, SGD-with-momentum update.
Function Documentation
◆ cnn_backward()
| void cnn_backward | ( | CNN * | net, |
| int | label ) |
Compute gradients via backpropagation.
Must be called after cnn_forward(). Accumulates gradients into net->grads.
- Parameters
-
net CNN after a forward pass. label True class index in [0, CNN_N_CLASSES).
- Note
- This is a stub: the full implementation is deferred.

◆ cnn_create()
| CNN * cnn_create | ( | void | ) |
Allocate and initialise a CNN with He-initialised weights.
All conv kernels and dense weights are drawn from a zero-mean normal distribution with variance 2/fan_in (He, 2015). Biases are zeroed.
- Returns
- Pointer to a heap-allocated CNN, or NULL on allocation failure.
- Note
- The caller must free the returned pointer with cnn_free().

◆ cnn_forward()
| void cnn_forward | ( | CNN * | net, |
| const float * | image ) |
Run a full forward pass and populate net->act.
Stages: Conv2D → ReLU → MaxPool → Flatten → Dense → ReLU → Dense → Softmax.
- Parameters
-
net Initialised CNN. image Flat array of CNN_IMG_H * CNN_IMG_W normalised float pixels, row-major order.
◆ cnn_free()
| void cnn_free | ( | CNN * | net | ) |
Free all memory associated with a CNN.
- Parameters
-
net Pointer returned by cnn_create(). No-op if NULL.
◆ cnn_loss()
| float cnn_loss | ( | const CNN * | net, |
| int | label ) |
Compute cross-entropy loss for the current forward-pass output.
loss = -log(output[label])
- Parameters
-
net CNN after cnn_forward(). label True class index.
- Returns
- Scalar cross-entropy loss (≥ 0).

◆ cnn_predict()
| int cnn_predict | ( | CNN * | net, |
| const float * | image ) |
Predict the most likely class for a single image.
Runs cnn_forward() internally.
- Parameters
-
net Initialised CNN with trained weights. image Flat float array, same layout as cnn_forward().
- Returns
- Class index in [0, CNN_N_CLASSES), i.e. 0 = 'A', 25 = 'Z'.
◆ cnn_update()
| void cnn_update | ( | CNN * | net | ) |
Apply one SGD-with-momentum update step to the weights.
w_new = w - lr * (β * v + g) where v is the momentum velocity and g is the gradient.
- Parameters
-
net CNN with filled net->grads from cnn_backward().
- Note
- Resets net->grads to zero after the update.

◆ cnn_zero_grads()
| void cnn_zero_grads | ( | CNN * | net | ) |
Zero all gradient accumulators in net->grads.
- Parameters
-
net CNN whose gradients should be cleared.

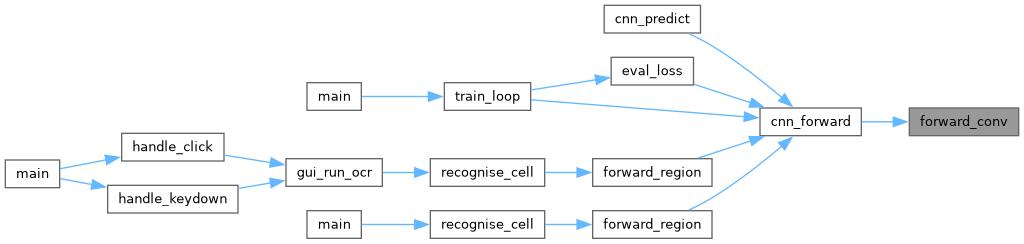
◆ forward_conv()
|
static |
Convolution stage: compute net->act.conv_out.
For each filter f and output position (r, c): conv_out[f][r][c] = bias[f] + sum_{dr,dc} kernel[f][dr][dc] * input[r+dr][c+dc]
- Parameters
-
net CNN with loaded weights and net->act.input filled.

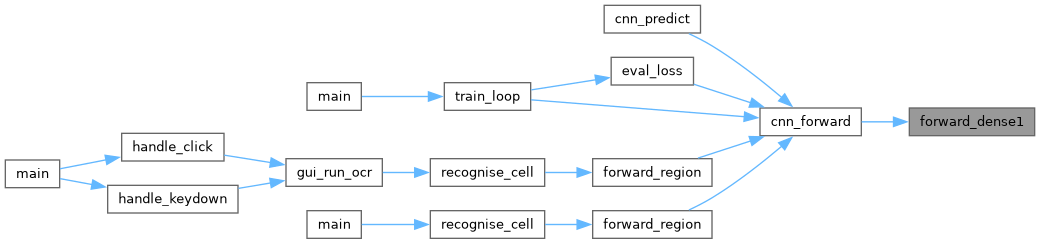
◆ forward_dense1()
|
static |
Dense layer 1 (2704 → 128) followed by ReLU.
z1[h] = b1[h] + sum_f W1[h][f] * flat[f] h1[h] = ReLU(z1[h])
- Parameters
-
net CNN after forward_flatten().
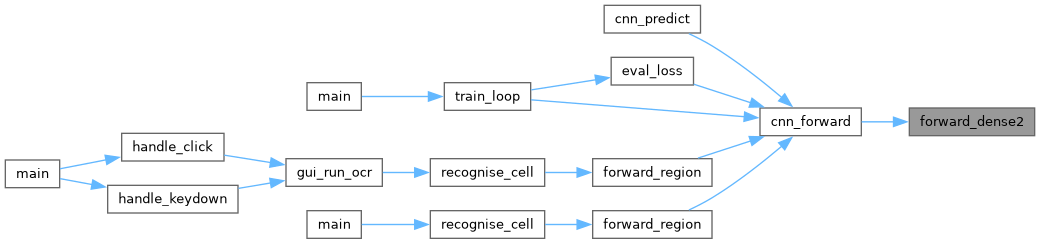
◆ forward_dense2()
|
static |
Dense layer 2 (128 → 26) followed by Softmax.
z2[k] = b2[k] + sum_h W2[k][h] * h1[h] output = softmax(z2)
- Parameters
-
net CNN after forward_dense1().

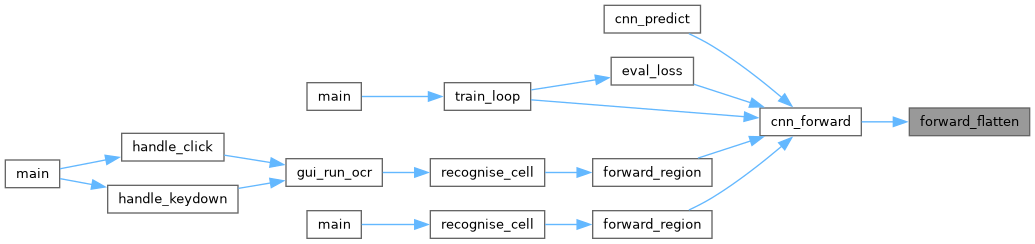
◆ forward_flatten()
|
static |
Flatten stage: copy pool_out into act->flat, row-major.
Index formula: flat[f * POOL_OUT_H * POOL_OUT_W + r * POOL_OUT_W + c]
- Parameters
-
net CNN after forward_pool().
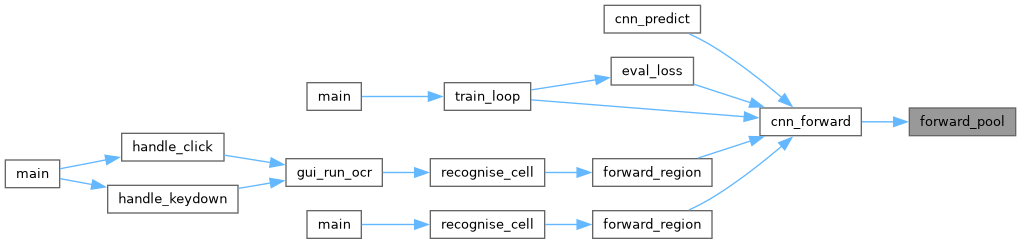
◆ forward_pool()
|
static |
Max-pooling stage: compute net->act.pool_out.
2×2 window, stride 2. Stores the winning row/col within each window in pool_max_r / pool_max_c for use during backprop.
- Parameters
-
net CNN after forward_conv().
◆ randn()
|
static |
Box-Muller transform: sample one value from N(0, 1).
Uses the standard two-uniform-samples formula. Not thread-safe due to static state; call from a single thread during initialisation.
- Returns
- One sample from the standard normal distribution.

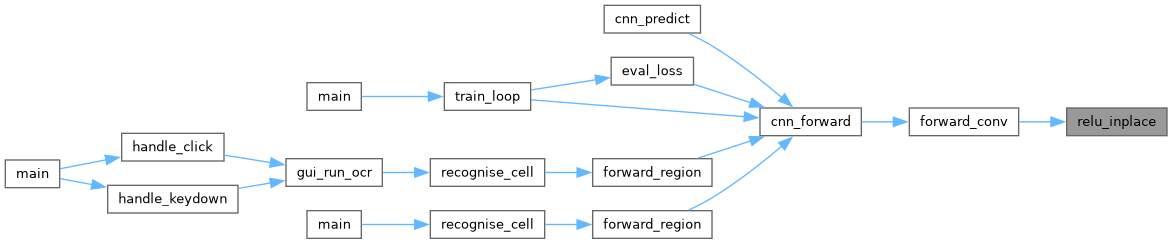
◆ relu_inplace()
|
static |
Apply ReLU element-wise: f(x) = max(0, x).
- Parameters
-
x Input/output array (modified in-place). length Number of elements.
◆ sgd_update()
|
static |
Apply SGD+momentum to one weight array.
For each weight w, velocity v, gradient g: v = β * v + g w -= lr * v
- Parameters
-
w Weight array (modified in-place). v Velocity array (modified in-place). g Gradient array (read-only). n Number of elements.

◆ softmax_inplace()
|
static |
Apply softmax in-place over an array of length n.
Subtracts the maximum value before exponentiation for numerical stability.
- Parameters
-
x Input/output array (modified in-place). length Number of elements.